KI erfordert qualitativ hochwertige Daten
Die steigende Produktivität durch Generative AI verstärkt die Priorisierung von KI- und ML-Initiativen.
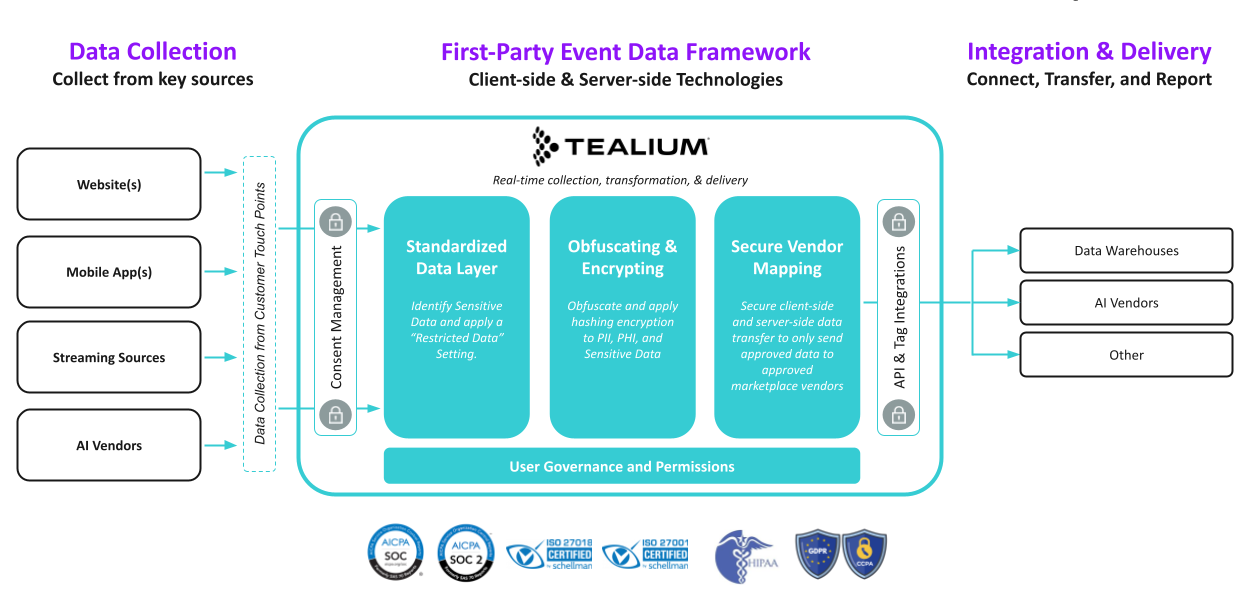
Modelle und KI-Infrastruktur werden zur Massenware und die Verfügbarkeit qualifizierter Ressourcen nimmt zu.Eine entscheidende Voraussetzung für den Erfolg besteht darin, dass “consented”, vorbereitete und gefilterte Daten für das Training, Feintuning und den Betrieb der Modelle verfügbar sind.
Die Einrichtung eines Data Collection Layer mit Flexibilität, Governance und Kontrolle ist unerlässlich und bleibt dabei dennoch komplex und fragmentiert. Die Anforderungen an Einhaltung und Transparenz in der KI werden in regulierten Branchen verstärkt.
Daten gestützte Differenzierung
Unternehmen haben zu denselben Modellen, Tools und Ressourcen Zugang, um ihre KI-Initiativen voranzutreiben. Ihre differenzierende Komponente liegt in den einzigartigen First-Party-Daten und ihrer effektiven Nutzung, um die passende Customer Experience zu gestalten und sich somit von anderen abzuheben.
Unternehmen, die über einen flexiblen, “consented” und zentralisierten Data Layer verfügen, haben somit einen Vorsprung. Um die Vorzüge von Machine Learning und KI effektiv zu nutzen, ist es unerlässlich, die Daten und die zugehörigen Pipelines so zu konfigurieren, dass sie nahtlos mit der KI-Infrastruktur und den übrigen Unternehmenskomponenten verbunden werden können.
Für regulierte Branchen hilft dies beim Risikomanagement und bietet gleichzeitig einen geregelten Weg zum KI-Erfolg.